This chapter builds on the principles presented in chapter 3. That chapter was ended with an example showing the relationship between two variables. In this chapter more predictor variables (independent variables) are added to the model. (Remember the Y'=a + bx is the model being considered.) There are no new principles added -- just complexity. In multiple there may be many independent variables and one dependent variable.
In this next section Y primed (Y'), Beta, regression line slope, and the constant are discussed. As implied in the formula Y'=a +bX these concepts are related.
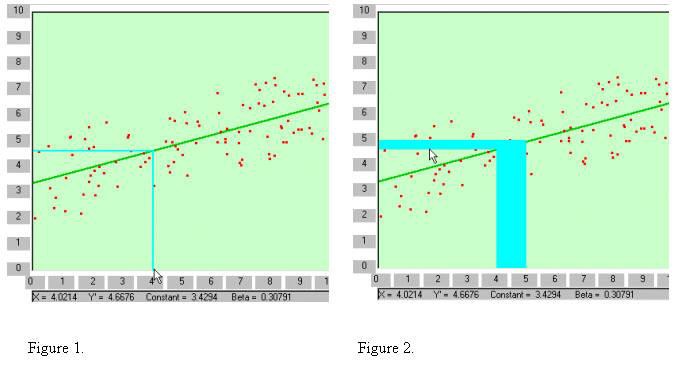
Beta is the change in Y for each unit (1) change of X. In the example above the change of X from 4 to 5 (actually 4.0214 to 5.0214) shows a change in Y as .30791. This is seen in Figure 2 by the light blue shaded area (if you are viewing in black and white it is the shaded area identified by the cursor). The vertical blue area represents 1 for X. That from 4 to 5. The left side of the blue area identifies 4 on the x-axis and when it meets the regression line a horizontal line to the y-axis is the Y value predicted by 4 on the x-axis (Y' for 4). The right side of the blue area identifies 5 on the x-axis and when it meets the regression line a horizontal line to the Y-axis is the Y value predicted by 5 on the X-axis (Y' for 5). The difference between Y' when X=4 and Y' when X=5 is beta. It is represented by the horizontal blue area.
The constant (a) is the value of Y when X is zero. It is 3.4294. It can be thought of as the origin or the regression line. Once the starting point of the regression line is identified (the constant--a)
the remainder can be generated by beta. That is the slope can be determined using beta. Points are plotted according the unit changes in X. The next plot after X=0 would be when X=1. A line is drawn from X=1 up to the point on Y that is equal to the constant plus beta. That is, 3.4294 plus .30791 which is 3.73731. Next .030791 is added to 3.73731 at the X=2 position and a point identified. Once these points are drawn the regression line can be drawn through these points as indicated above.
With this information a prediction can be made by using Y'. That is if X is known and one has the constant and beta then Y can be predicted using the following formula:
Y'=a + bX.
The difference between Y' and the actual score is the error in prediction. When all of the differences are squared and summed the result is the error sum of squares. The square root of the sum of squares error divided by N is the error variance.
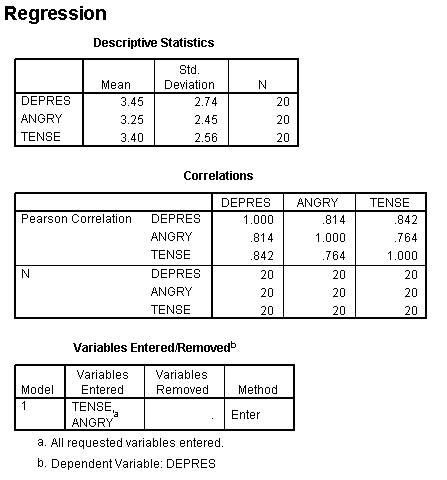
In chapter 3 the two variables DEPRES and TENSE (taken from the Psychosocial Assessment Scale) were correlated using the regression method. In this example the variable ANGRY is added to the model. The variable DEPRES will be treated as the criterion variable (dependent variable); while TENSE and ANGRY will be treated at the predictor variables (independent variables).
The following data is taken from the data found in Figure 1 in chapter.
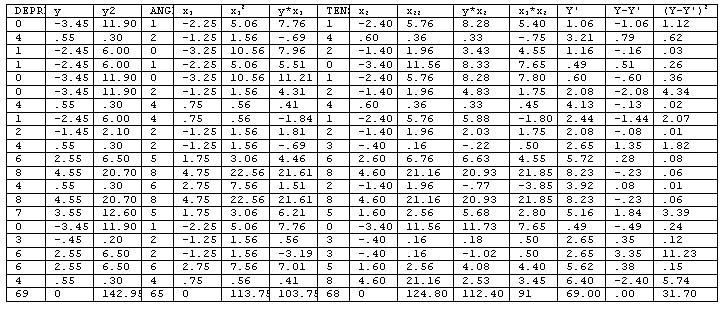
Although all of the formulae presented in chapter 3 apply here only the extended formulae related to multiple variables.

Notice that the results of these cases corresponds to the column identified as Y' (y primed) in the table above.


R square and consequently the amount of shared variance between two or more variables can be obtained by (1) squaring the correlation and (2) multiplying that result time 100.
Click Continue Click Paste
That will produce approximately the following syntax file (the "keep" command will not be there).

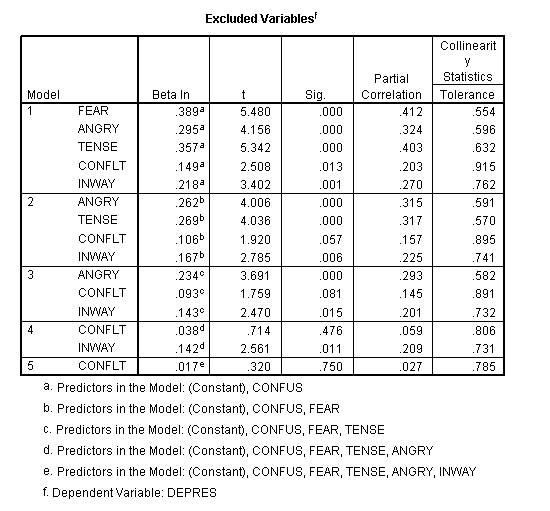
This next set of examples is designed to show (1) that you can test the contribution of each variable, (2) that you can force variables to enter the model (a new concept model) to be tested for their contribution, and (3) that the computer will select the next variable that will contribute the most to model (step wise regression).
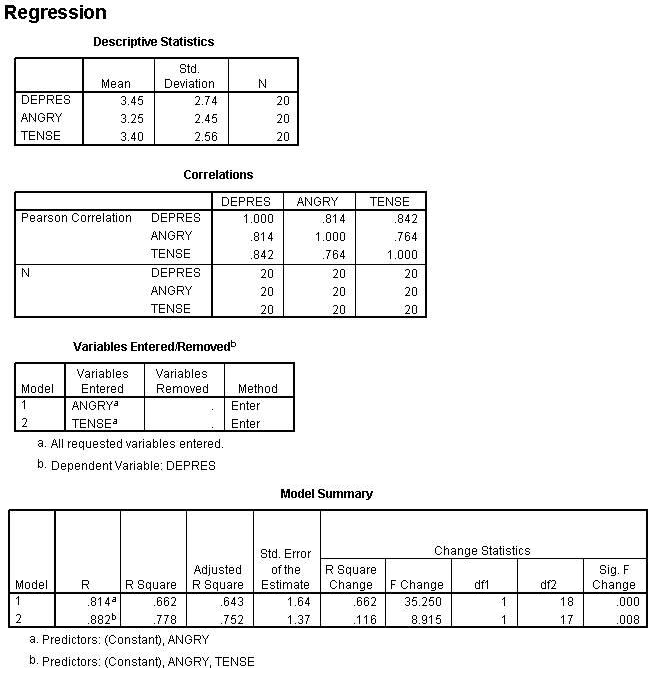
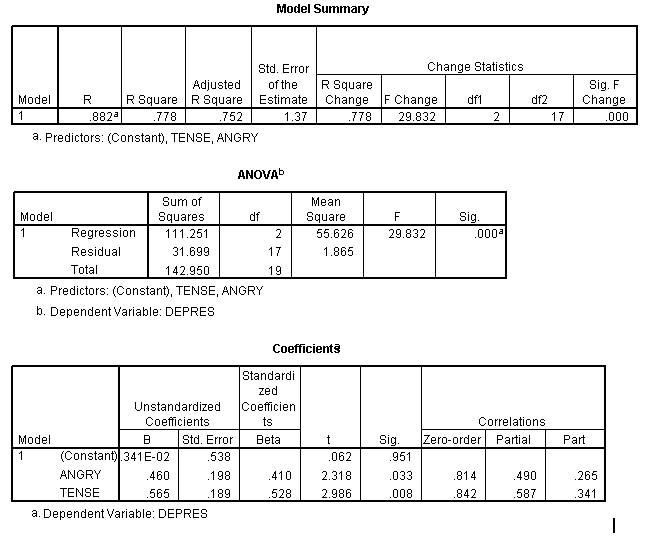
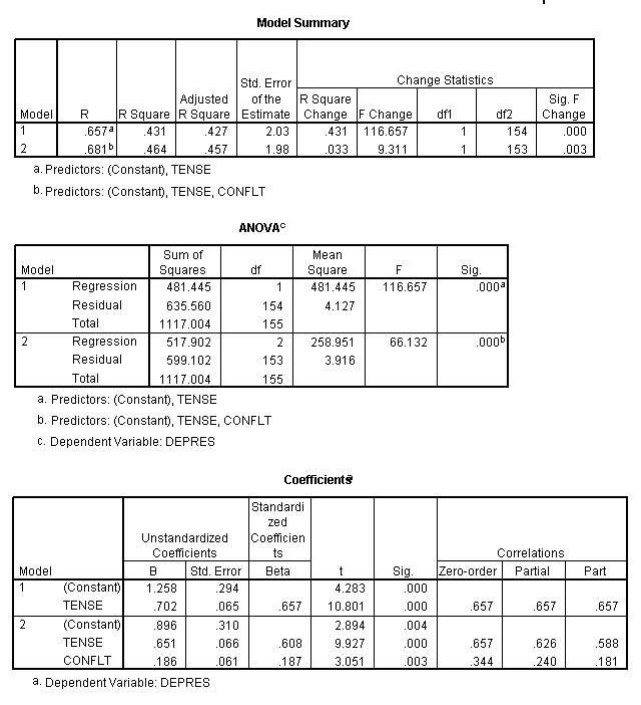
Notice that the R Square Change for variable 2 (Tense) is .116. That is the proportion of change and can be converted to percentage of variance accounted for by multiplying by 100 which makes it 11.6% when rounded becomes 12%. This variance is referred to as unique variance. It is variance of the Y variable that is shared only with Tense. Or stated differently it is variance of the Y variable that is accounted by Tense only.
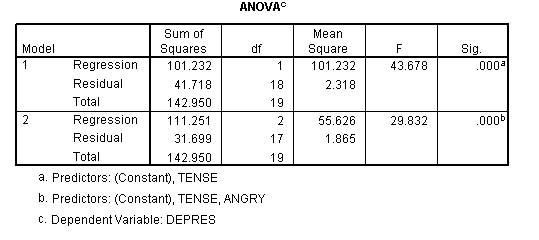
ANOVA0
Mode | l | Sum of Squares | df | Mean Square | F | Sig. |
1 | Regression | 94.629 | 1 | 94.629 | 35.250 | .ooo• |
Residual | 48.321 | 18 | 2.684 | |||
Total | 142.950 | 19 | ||||
2 | Regression | 111.251 | 2 | 55.626 | 29.832 | .ooob |
Residual | 31.699 | 17 | 1.865 | |||
Total | 142.950 | 19 |
Predictors: (Constant),ANGRY
Predictors: (Constant),ANGRY, TENSE
Dependent Variable: DEPRES
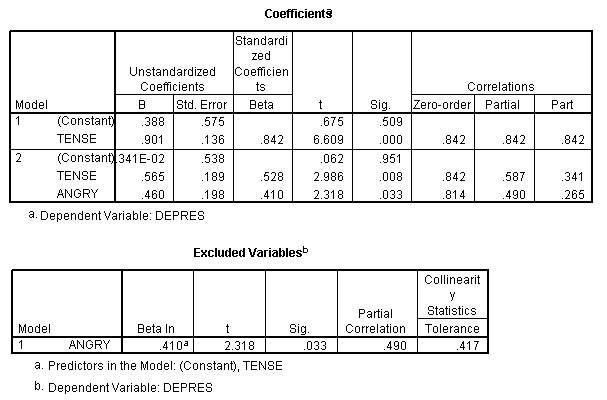
Coefficients>
Model | Unstandardized Coefficients | Standardi zed Coefficien ts | t | Sig. | Correlations | ||||
8 | Std. Error | Beta | Zero-order | Partial | Part | ||||
1 | (Constant) | .486 | .619 | .814 | .784 | .443 | .814 | .814 | .814 |
ANGRY | .912 | .154 | 5.937 | .000 | |||||
2 | (Constant) | .341E-02 | .538 | .410 | .062 | .951 | .814 | .490 | .265 |
ANGRY | .460 | .198 | 2.318 | .033 | |||||
TENSE | .565 | .189 | .528 | 2.986 | .008 | .842 | .587 | .341 | |
Dependent Variable: DEPRES

File Name = crsreg16. sps
get file = 'e:\dape\CRSLEQl.sav'lkeep=
GROUP LEISUR FEAR DEPRES FEELG ANGRY CONFUS WORTH TENSE USELES SATISF OUTSID BILLS TALKTO CONFLT ALCDRG SUPPRT EJ:.APLOY GOODJ LIKEW INWAY MONEY HEALTH
DISTRS QUALIT RELATE JOB ABUSE sLFCAR REGRESSION
VARIABLES = DEPRES ANGRY TENSE
/STATISTICS = R COEFF ANOVA OUTS ZPP CHA
/DEPENDENT=DEPRES
IMETHOD=enter tense
/method=enter angry.
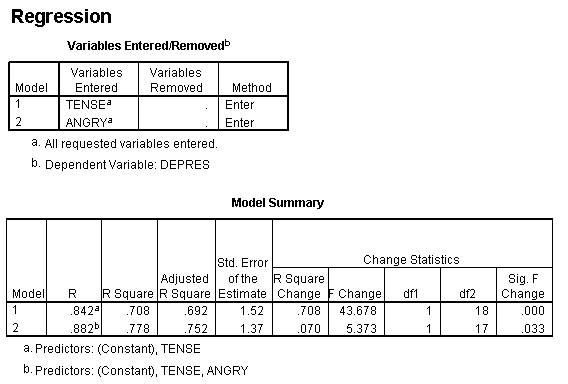
Notice that the R Square Change for variable 2 (Angry) is .070. That is the proportion of change and can be converted to percentage of variance accounted for by multiplying by 100 which makes it 7 or 7%.
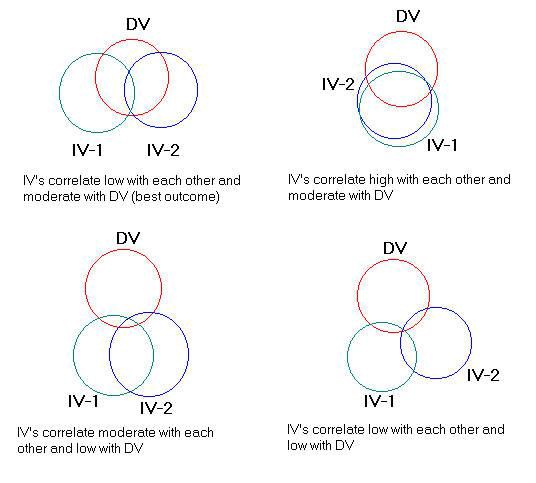
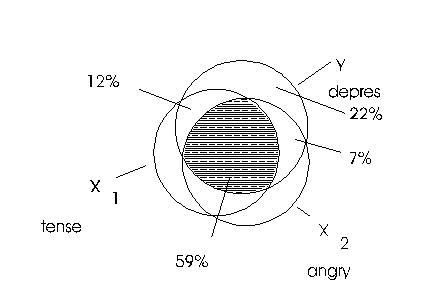
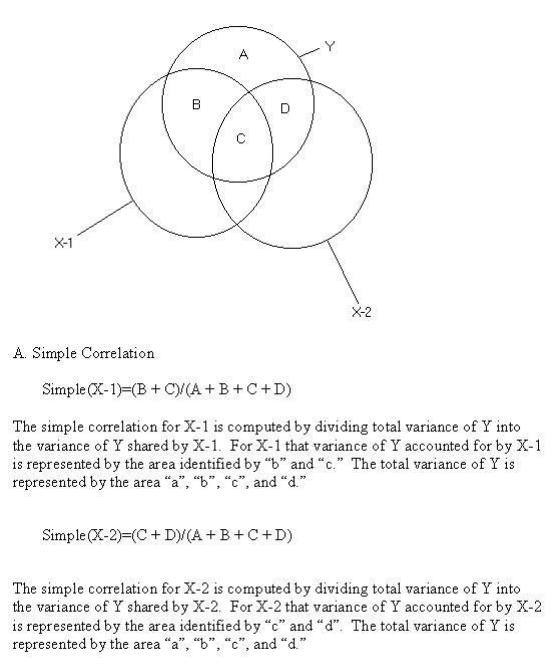
In the first run Tense accounted for 12% variance beyond Anger and in the second run Anger accounted for 7% variance beyond Tense. These two runs are represented in the Venn diagram below. These percentages can be shown in a Venn diagram. Overlaps of variables indicate shared variance. For example, in the figure below there is 12% overlap between the X-1 variable and the Y variable.
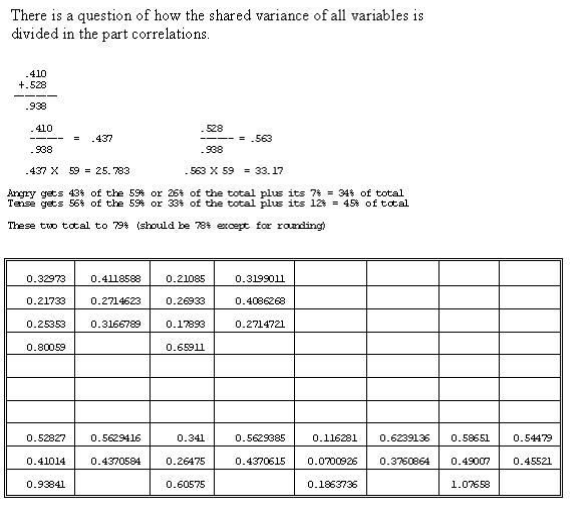
It appears that it makes no difference whether you think about the beta weight as being taken directly from the part correlation or whether you take the part correlations plus the respective amount of weight from the overlap -- the proportional weight is the same.



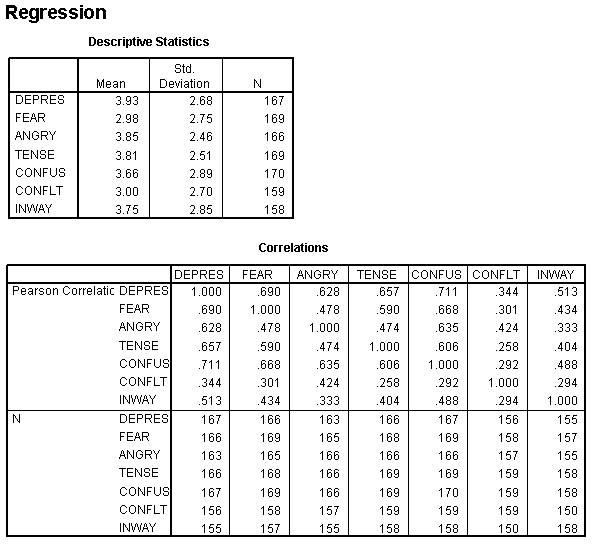
Model Summary
Model | R | R Square | Adjusted R Square | Std. Error oflhe Estimate | Change Statistics | ||||
R Square Change | F Change | df1 | df2 | Sig. F Change | |||||
1 | .711' | .505 | .502 | 1.90 | .505 | 150.997 | 1 | 148 | .000 |
2 | .767b | .589 | .583 | 1.73 | .084 | 30.034 | 1 | 147 | .000 |
3 | .794° | .630 | .623 | 1.65 | .041 | 16.287 | 1 | 146 | .000 |
4 | .814d | .662 | .653 | 1.58 | .032 | 13.626 | 1 | 145 | .000 |
5 | .823• | .677 | .665 | 1.55 | .015 | 6.556 | 1 | 144 | .011 |
Predictors: (Constant), CONFUS
Predictors: (Constant), CONFUS, FEAR
Predictors: (Constant), CONFUS, FEAR, TENSE
Predictors: (Constant), CONFUS, FEAR, TENSE, ANGRY
Predictors: (Constant), CONFUS, FEAR, TENSE, ANGRY, INWAY
Coefficients>
Model | Unstandardized Coett cients | Standardi zed Coefficien ts | t | Sig. | Correlations | ||||
8 | Std. Error | Beta | Zero-order | Partial | Part | ||||
1 | (Constant) | 1.514 | .245 | .711 | 6.177 | .000 | .711 | .711 | .711 |
CONFUS | .660 | .054 | 12.288 | .000 | |||||
2 | (Constant) | 1.265 | .229 | .451 | 5.535 | .000 | .711 | .464 | .335 |
CONFUS | .419 | .066 | 6.342 | .000 | |||||
FEAR | .380 | .069 | .389 | 5.480 | .000 | .690 | .412 | .290 | |
3 | (Constant) | .782 | .248 | .348 | 3.148 | .002 | .711 | .370 | .242 |
CONFUS | .323 | .067 | 4.810 | .000 | |||||
FEAR | .292 | .070 | .299 | 4.204 | .000 | .690 | .329 | .212 | |
TENSE | .288 | .071 | .269 | 4.036 | .000 | .657 | .317 | .203 | |
4 | (Constant) | .371 | .263 | .226 | 1.412 | .160 | .711 | .237 | .142 |
CONFUS | .210 | .071 | 2.936 | .004 | |||||
FEAR | .280 | .067 | .286 | 4.185 | .000 | .690 | .328 | .202 | |
TENSE | .257 | .069 | .240 | 3.723 | .000 | .657 | .295 | .180 | |
ANGRY | .255 | .069 | .234 | 3.691 | .000 | .628 | .293 | .178 | |
5 | (Constant) | .157 | .271 | .182 | .580 | .563 | .711 | .193 | .112 |
CONFUS | .169 | .072 | 2.355 | .020 | |||||
FEAR | .259 | .066 | .265 | 3.913 | .000 | .690 | .310 | .185 | |
TENSE | .238 | .068 | .222 | 3.490 | .001 | .657 | .279 | .165 | |
ANGRY | .254 | .068 | .233 | 3.749 | .000 | .628 | .298 | .178 | |
INWAY | .134 | .052 | .142 | 2.561 | .011 | .513 | .209 | .121 | |
a. Dependent Variable: DEPRES

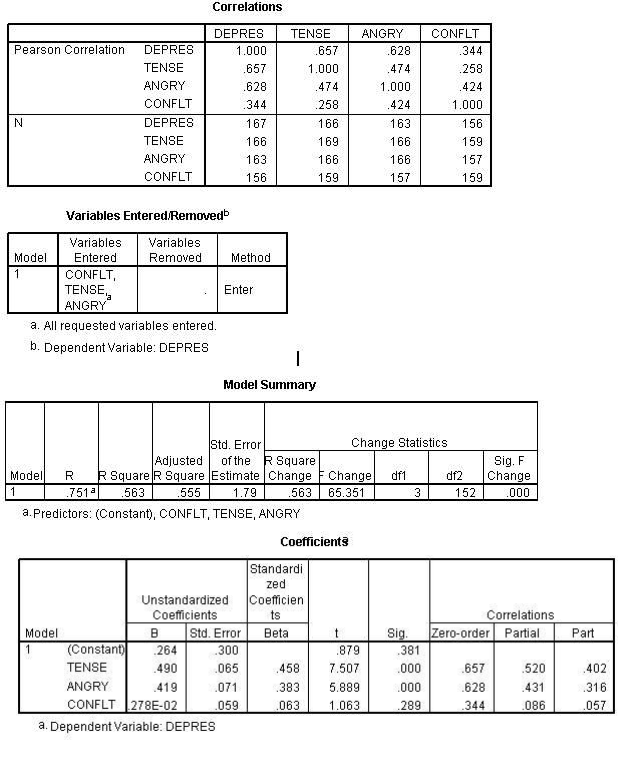
File Name = crsreg24. sps
get file = 'e:\dape\CRSLEQ31.sav'ikeep=
AGE SEX GROUP LEISUR FEAR DEPRES FEELG ANGRY CONFUS WORTH TENSE USELES SATISF OUTSID
BILLS TALKTO CONFLT ALCDRG HUMOR SUPPRT EMPLOY GOODJ LIKEW INWAY MONEY HEALTH DIFFNT CHANGE SENSE
J:...ITSSING VALUES AGE (999).
J:...ITSSING VALUES SEX TO HEALTH (9). REGRESSION
DESCRIPTIVES=MEAN STDDEV CORR N
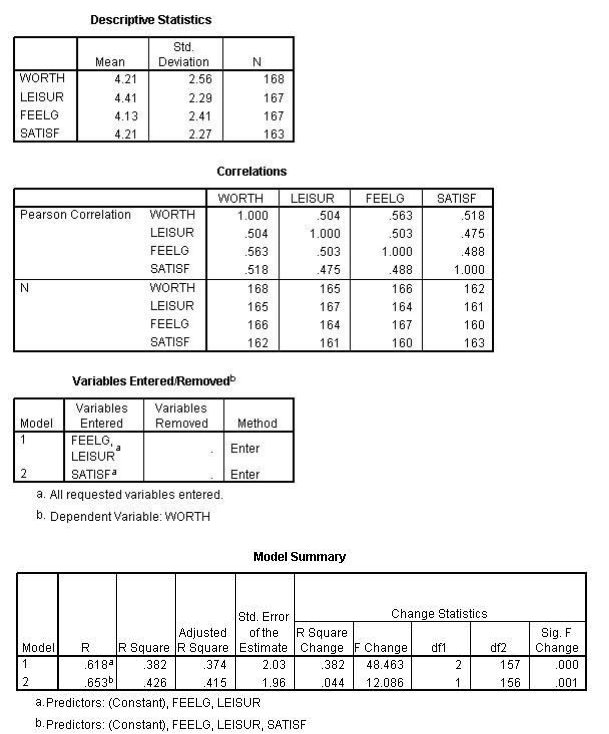
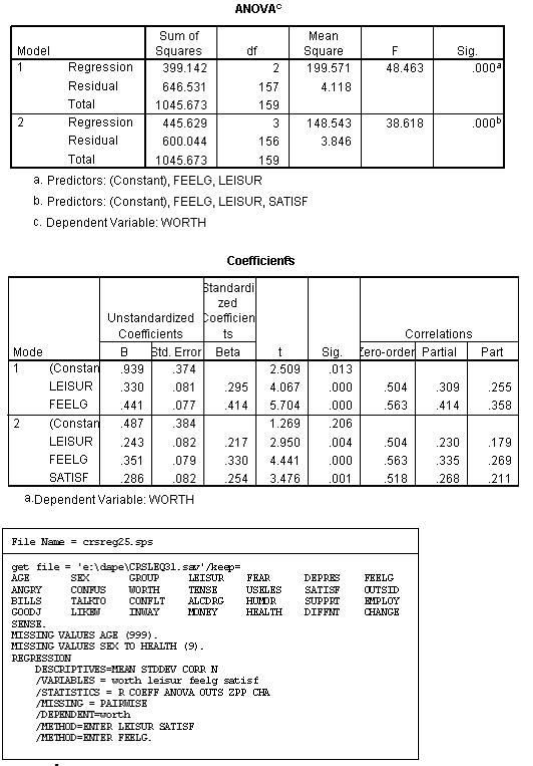
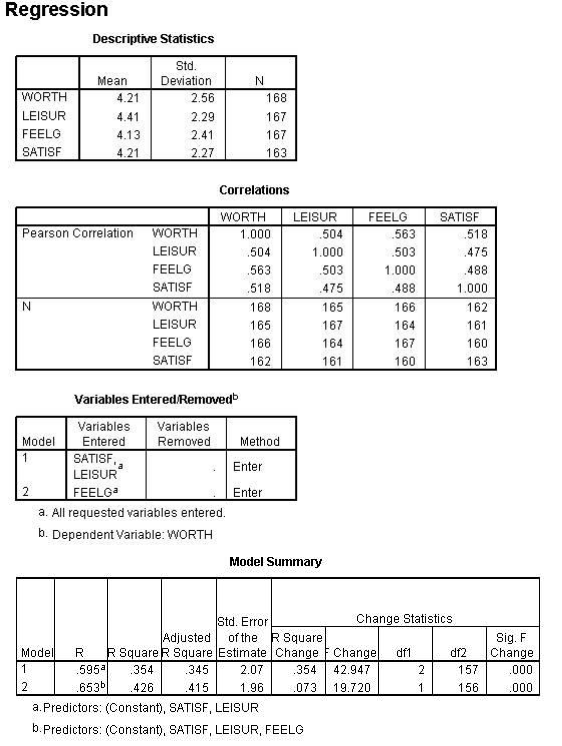
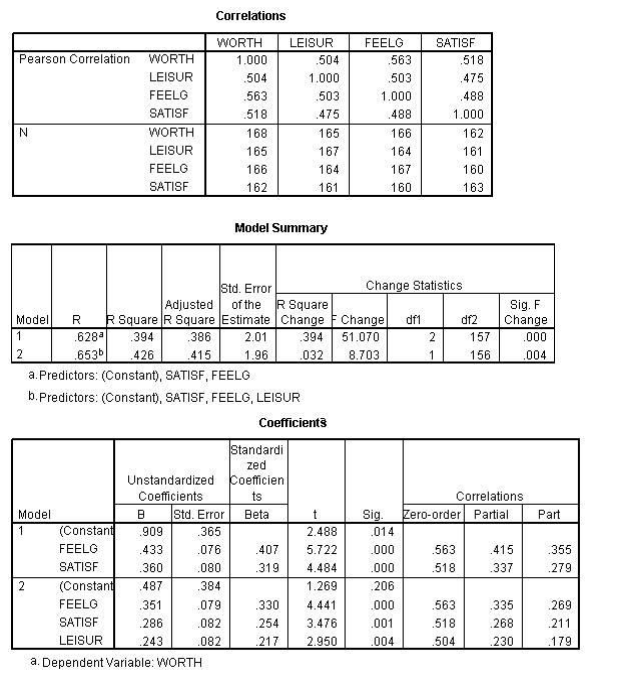
N ARIABLES = worth leisur feelg satisf
/STATISTICS = R COEFF ANOVA OUTS ZPP CHA OOSSING = PAIRWISE
/DEPENDENT=worth
/METHOD=ENTER LEISUR FEELG
IMETHOD=ENTER satisf

Beta Weights (Regression Coefficients)
The beta weight of a multiple correlation splits the overlap correlations of two independent variables. It does not correspond to the part or partial correlations. Each does not account for the overlap of the two independent variables.
Using Multiple Regression in Science
Select type of regression
Empirical (must cross-validate)
forward steps
backward steps
Theoretical
single variable steps
variable category steps
Split sample for cross validation (test for alternative hypotheses)
Ifyou have too many variables it is possible that none are significant
Interpretations of beta
rate of change in dedpendent variable from predictor, when others are held constant (in standard score form only).
given assumptions are met (measure all predictors or those not measured are not correlated with those you do) beta gives causal contributions to relationship.
if significant, beta means that a predictor has a unique contribution.
Beta is a sort of standardized "usefulness" = usefulness I degree of non-redundant information given by predictor
beta's may be compared within a regression equation for size in terms of rate of
change in criterion.
Usefulness = the amount of multiple correlation squared drops if you eliminate a variablt (R-square change).
unique contribution of prediction in terms of proportion of independent variable explained.
2. the part correlation squared when other variables have been removed.
ill.Characteristics of the correlation and regression
A. The optimal relationship between the independent variables and dependent variable when the independent variables correlate low with each other and moderate with the dependent variable.